Span Team
Your coding agents already know what's making their jobs harder. The problem is that the signal is scattered across thousands of sessions.
Today, we’re unveiling Environment Readiness: a synthesized view of what to fix in your environment to improve agentic performance based on feedback from agent sessions across your organization. This is the latest entry in our AI Effectiveness Suite, which includes the Effectiveness Scorecard and Spotlights — all powered by agent traces and agent evals.
Why the environment matters
Conversations about AI effectiveness usually center on the developer — how they prompt, which model they choose, how they structure their work. This matters, but agent performance is also shaped by everything around the agent: the codebase, documentation, tool access, verification workflows, repo structure, instruction files. When the environment is suboptimal, even strong developers using the latest models will struggle.
That makes the environment one of the highest-leverage places to invest. Environment quality improves outcomes across every session — for every agent and every developer using them. A single fix — be it more detailed documentation or access to a tool that agents keep reaching for — can compound across thousands of future runs.
What leaders see
Environment Readiness examines agent traces and evals from sessions to break down what context was missing, what made the workflow break down, and what would have improved the outcome. Because this runs across many sessions and across different coding agents, the result is a synthesized view of where the environment is helping or hurting agent performance.
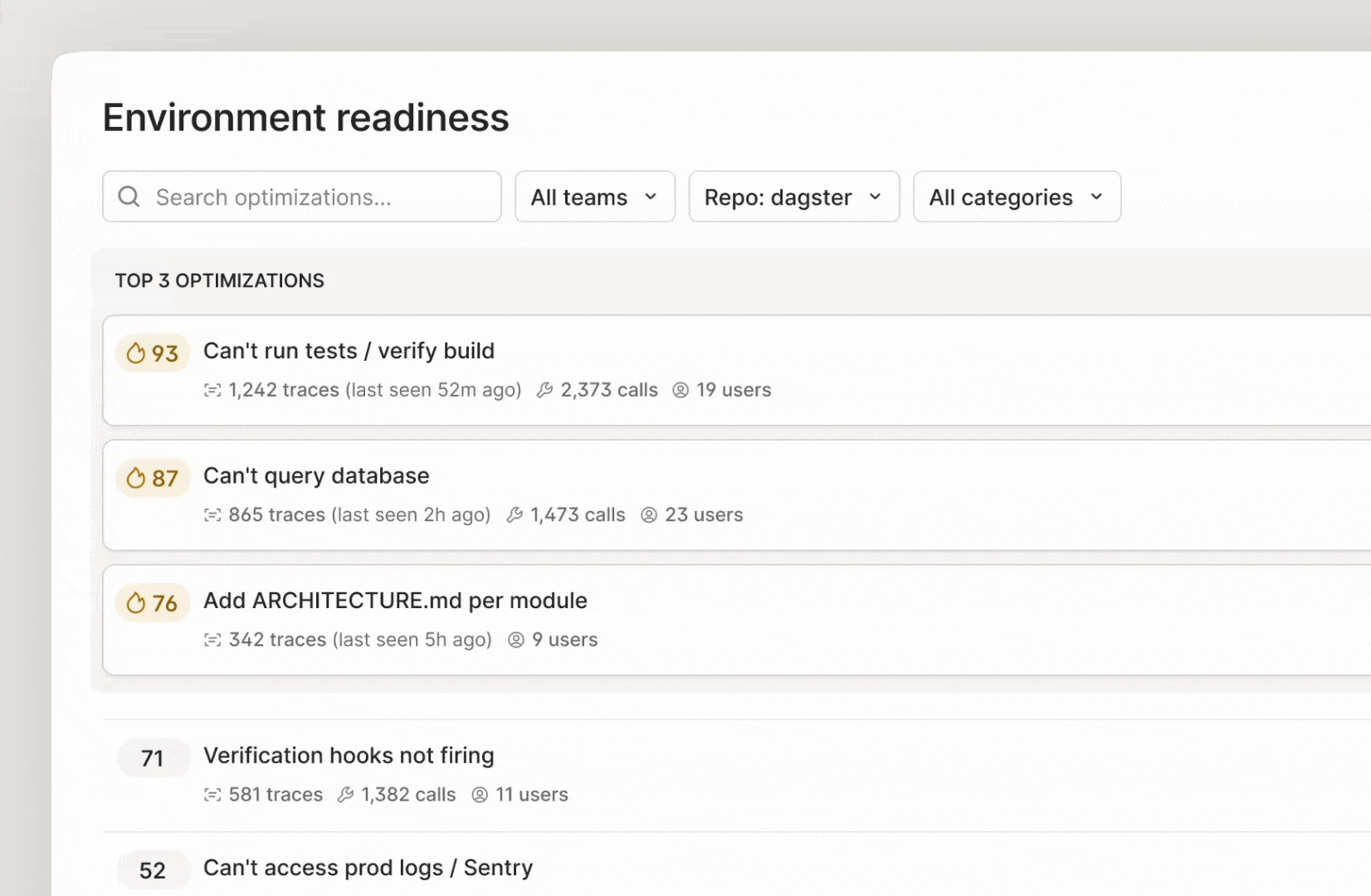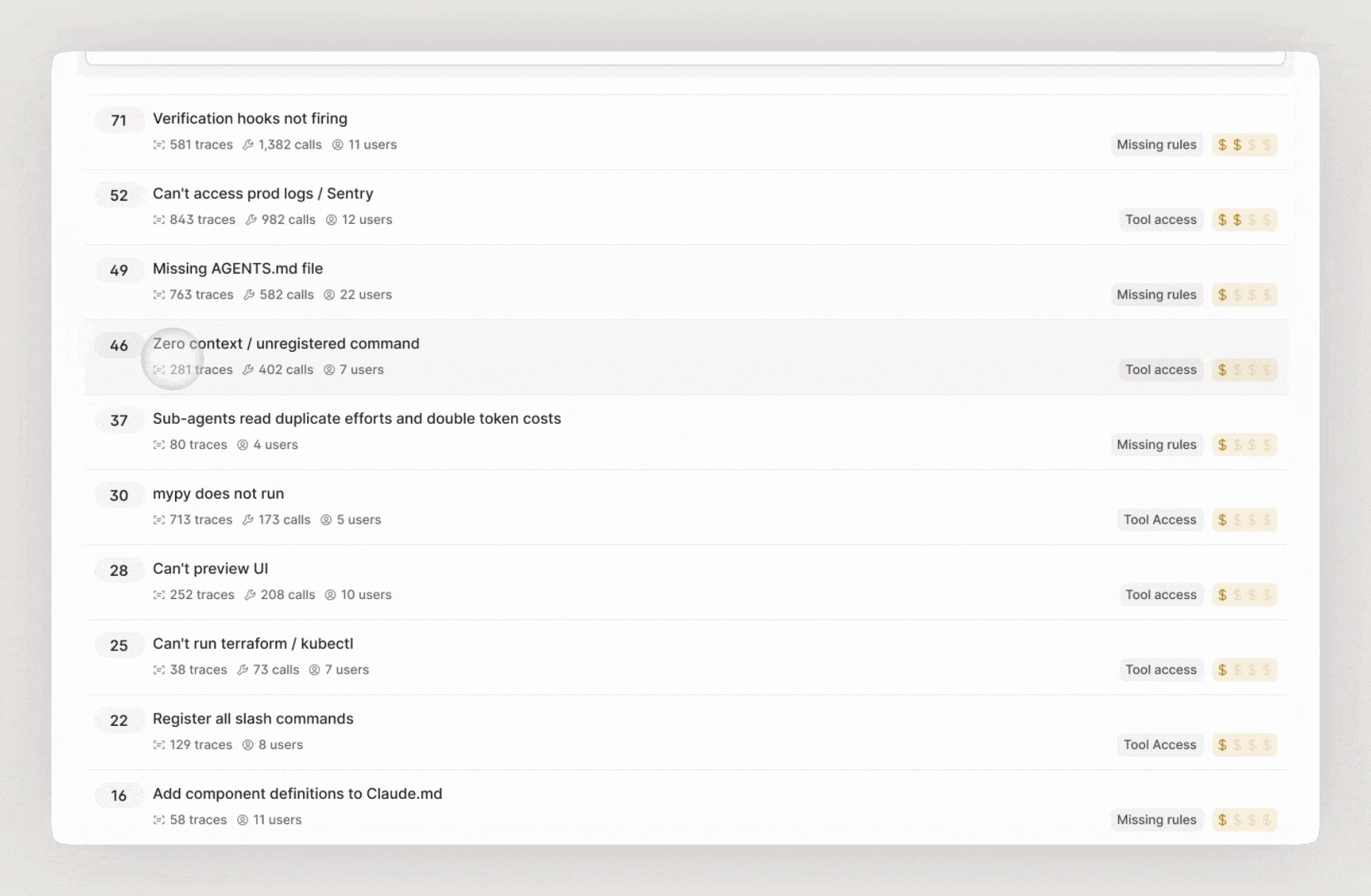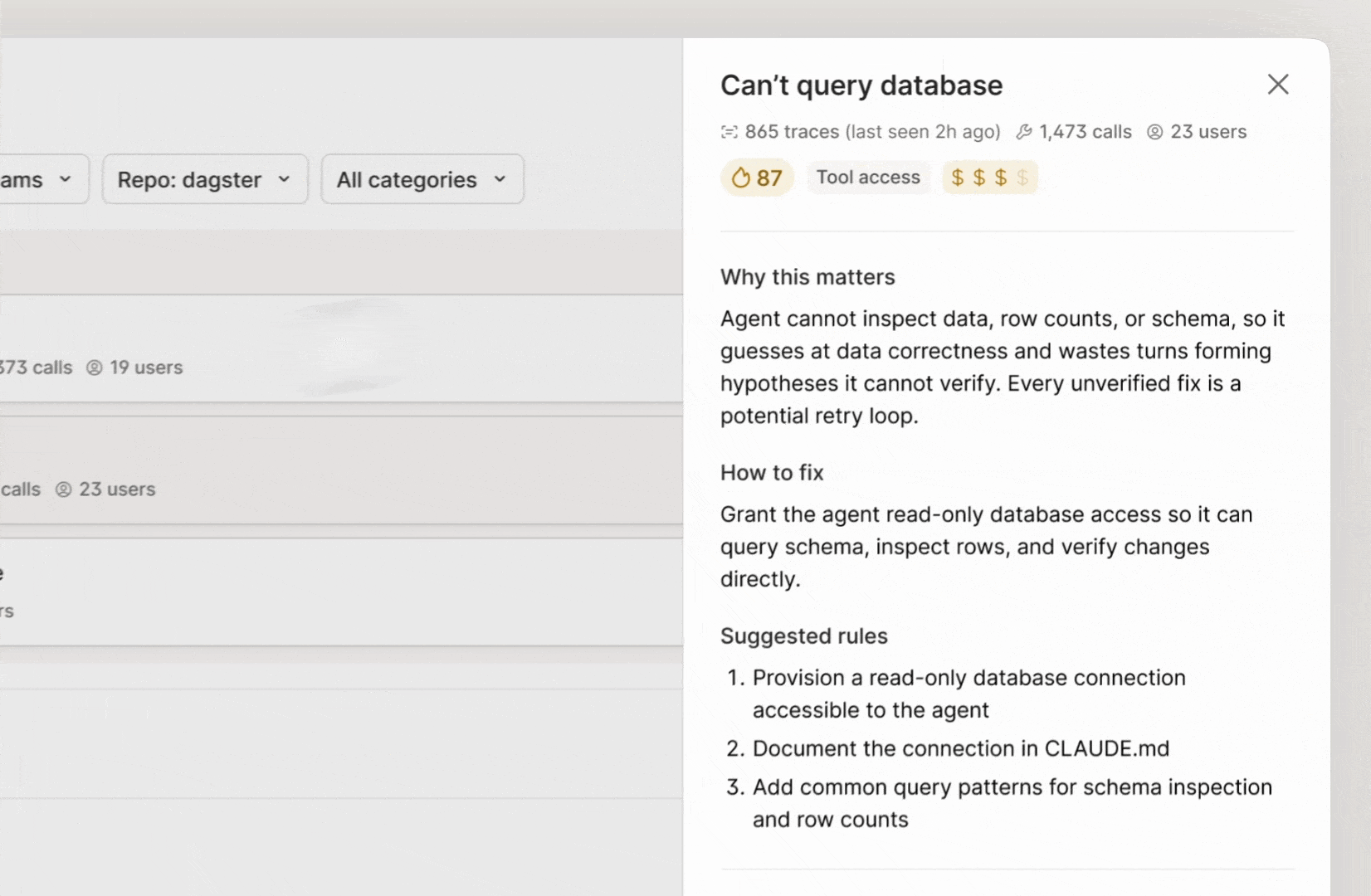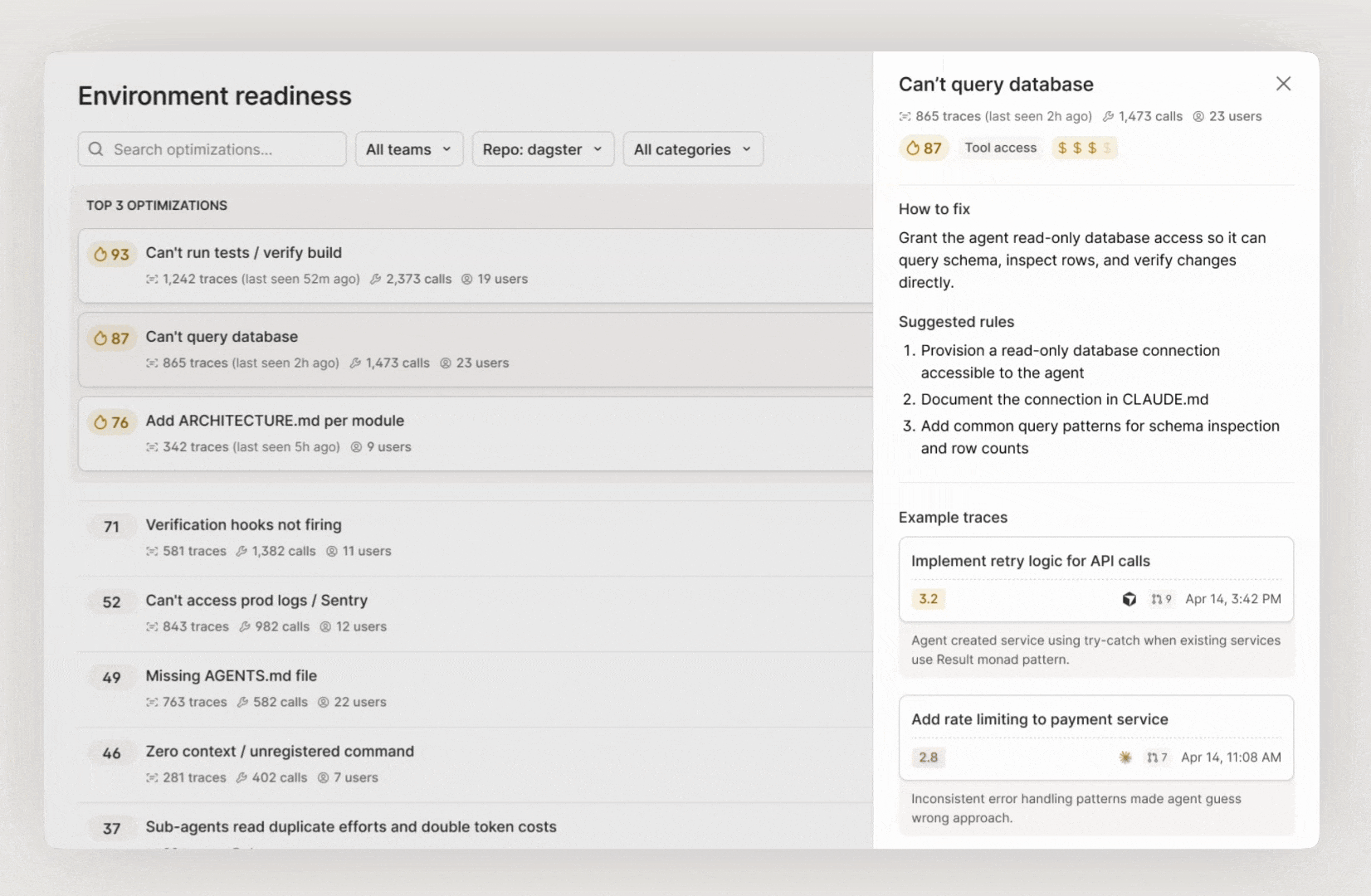
The output is a prioritized list of recommendations based on evals that you can filter by repo. Each recommendation is backed by evidence: how many traces pointed to the issue, what kinds of tasks were affected, and the expected impact of the fix. You can also see the estimated token savings for each recommendation to prioritize based on cost impact.
Recommendations typically fall into a few categories that can include:
Adding a missing skill to the agent's instruction file, or giving the agent access to one when it doesn't have the skill
Removing unnecessary iterations by giving an agent access to key CLIs, instating missing test harnesses, and improving slow verification paths
Minimize coordination gaps that result in inefficient token usage — for example, a sub-agent reads a file, then the parent agent reads the same file again because it didn't know the work had already been done.
Closing the loop
The Effectiveness Scorecard gave leaders a baseline. Spotlights surfaced the practices worth spreading. Environment Readiness completes the picture by pointing at the environment itself — often the actual bottleneck, and the hardest to see from any single session.
When the environment improves, the signal scattered across thousands of sessions becomes a single, prioritized place to start.