Insights
Quality in the Age of AI
Span Research Team
Among engineering organizations with similar levels of AI adoption, the ones with the lowest defect rates aren’t the ones with the most process. They’re the ones with the most team autonomy, the smallest PRs, and the healthiest codebases.
Here’s a puzzle from our dataset.
We studied a selected sample of engineering organizations that have meaningfully adopted AI code generation tools — between 36% and 63% of their pull requests contain AI-generated code. Same class of tools. Similar adoption curves. Comparable team sizes.
Yet their defect rates vary by nearly 50%. One group averages 6.5% of PRs introducing production defects. The other averages 9.5%.
The natural assumption is that the lower-defect group must be using AI differently — more conservatively, on simpler tasks, with heavier guardrails. The data says otherwise.
AI usage is virtually identical
AI Code Bucket | Low-Defect Group | High-Defect Group |
|---|---|---|
0-5% (mostly human) | 32.6% | 32.1% |
5-25% | 16.2% | 16.9% |
25-50% | 21.5% | 21.1% |
50-100% (mostly AI) | 29.7% | 29.8% |
The natural assumption is that the lower-defect group must be using AI differently — more conservatively, on simpler tasks, with heavier guardrails. The data says otherwise.
3 Structural Differences That Determine High Performance
Autonomous teams with clear ownership
The clearest signal in our data is about team structure, not process volume.
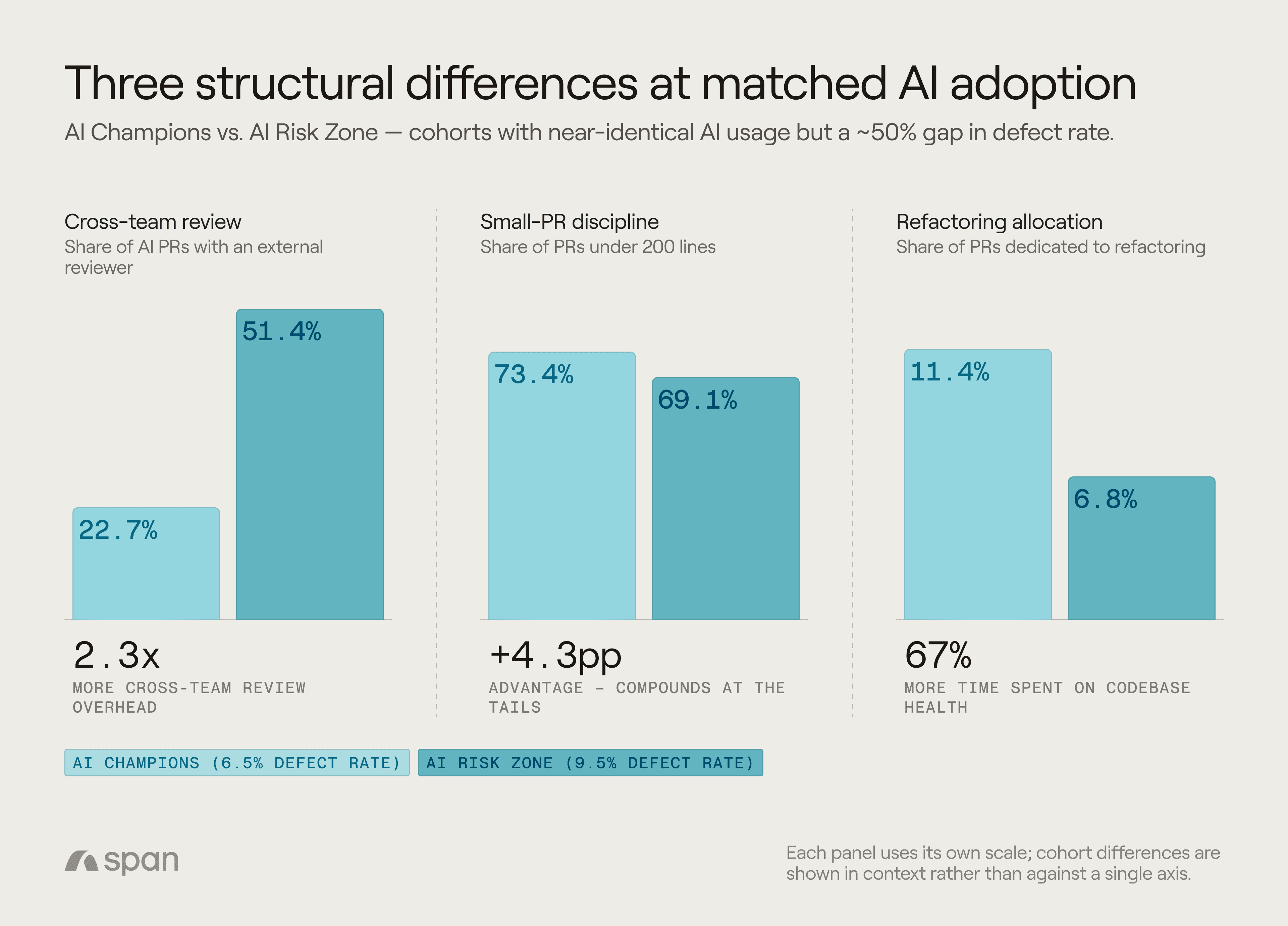
In the low-defect group, 22.7% of AI-assisted PRs involve a cross-team reviewer. In the high-defect group, it’s 51.4% — more than double.
This isn’t about review quality. It’s about ownership boundaries.
When half of your AI-assisted PRs require someone outside the team to review the code, it signals one of two things: either teams don’t have clear ownership of their domain, or the architecture creates so many cross-cutting dependencies that no change is truly local. Both are structural problems that AI amplifies.
AI code generation tools work best when they operate within a well-defined context. When a single PR touches multiple team boundaries, AI loses the contextual constraints that make its output reliable. The code compiles, the tests pass, but the interaction between components introduces subtle integration bugs that no single reviewer fully understands.
Organizations where teams own their domain end-to-end — from API to data layer to deployment — can absorb AI-generated code more safely. The developer who prompts the AI tool is the domain expert. They catch the wrong return type because they know what the caller expects. They notice the missing null check because they’ve seen that upstream API return null before.
Organizations with tangled ownership boundaries lose this advantage. The AI generates code that looks correct to the author, gets waved through by a cross-team reviewer who lacks context, and breaks in production when it interacts with a dependency the AI didn’t know about.
Small PRs as a discipline, not just a preference
Low-defect organizations ship 73.4% of their PRs under 200 lines. High-defect organizations ship 69.1% — a modest gap in percentage, but one that compounds dramatically.
Size Percentile | Low-Defect | High-Defect |
|---|---|---|
P25 | 13 lines | 14 lines |
P50 (median) | 62 lines | 74 lines |
P75 | 214 lines | 268 lines |
P90 | 548 lines | 720 lines |
PR size is the single strongest predictor of defect rates in our dataset — XL PRs (1,000+ lines) introduce bugs at 5.9x the rate of XS PRs, and this effect holds even after normalizing for line count: larger PRs have a higher defect rate per line, not just more defects in absolute terms. This finding holds across every organization we studied, regardless of AI adoption level.
But what makes this interesting in the AI context is the interaction effect. AI tools make it easy to generate large PRs. A developer who would manually write 200 lines can prompt an AI tool to generate 800. Without a cultural norm around PR size, AI adoption naturally pushes PRs larger — and larger PRs mean more bugs.
Low-defect organizations appear to have maintained small-PR discipline despite AI making it easy to go bigger. This is a deliberate practice, not an accident. It means breaking AI-generated output into reviewable chunks rather than shipping everything the AI produces in one go.
Refactoring over firefighting
The most underappreciated difference is in how teams allocate their engineering time.
PR Type | Low-Defect | High-Defect |
|---|---|---|
Bugfix | 21.0% | 27.3% |
Refactoring | 11.4% | 6.8% |
New functionality | 27.9% | 27.9% |
Both groups ship the same proportion of new features (27.9%). But low-defect organizations spend 67% more of their PRs on refactoring and 23% less on bugfixes.
This creates a feedback loop:
Low-defect cycle: Clean codebase → AI generates coherent code → fewer bugs → less firefighting → more time for refactoring → cleaner codebase.
High-defect cycle: Brittle codebase → AI generates code that interacts with fragile dependencies → more bugs → more firefighting → no time for cleanup → more brittle codebase.
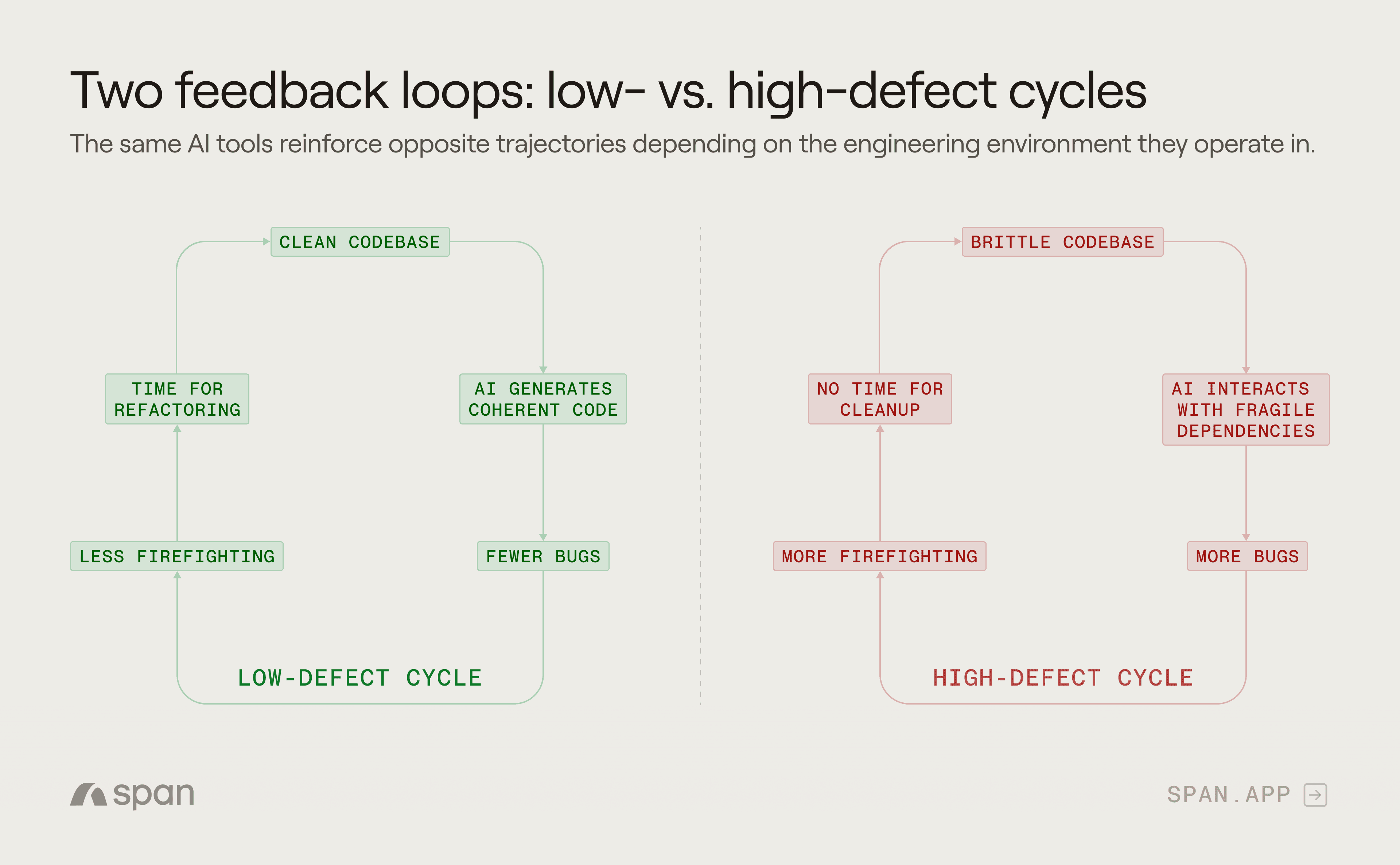
AI doesn’t create these cycles. But it accelerates whichever one you’re in. In a well-maintained codebase, AI can generate a new API endpoint that slots in cleanly. In a codebase with inconsistent patterns, implicit dependencies, and untested edge cases, the same AI prompt produces code that compiles and passes tests but breaks something downstream.
The refactoring investment isn’t about code aesthetics. It’s about maintaining the contextual clarity that AI tools depend on to generate reliable output.
The AI Slop Trap
There’s a growing concept in engineering: AI slop — code that an AI generates which looks complete, compiles, passes tests, and even reads well on review, but contains subtle defects.
Our defect taxonomy (see: The Defect Fingerprint) shows that AI-specific bugs cluster around exactly these issues — return value errors, null handling, and state management. These are bugs that survive shallow review because the code looks correct.
High-defect organizations are more vulnerable to AI slop — not because their reviews are worse per se, but because the structural conditions make AI slop harder to catch:
Cross-cutting PRs mean the reviewer may not know the domain well enough to spot a wrong return type
Large PRs mean the reviewer is scanning 500 lines instead of deeply understanding 100
Brittle codebases mean there are more implicit contracts the AI can violate without the reviewer noticing
Low-defect organizations mitigate AI slop structurally:
Team-local PRs mean the reviewer is the domain expert
Small PRs mean there’s less code to scrutinize and more attention per line
Clean codebases mean the patterns are consistent and deviations are visible
This is the core insight: the defense against AI slop is not more review. It is engineering conditions that make review effective.
What Does This Mean For Your Organization?
If your team is scaling AI adoption and watching defect rates rise, the natural instinct is to add gates — require more reviewers, mandate cross-team sign-off, enforce formal approval on every PR. Our data suggests this is precisely the wrong response.
The organizations with 96.5% formal approval rates and 51.4% cross-team review rates are the ones with the highest defect rates. Not because those practices are inherently bad, but because applied universally, they dilute attention and create a false sense of safety.
The alternative is structural:
Invest in team autonomy. Teams that own their domain end-to-end can review AI-generated code with the context needed to catch AI slop. Cross-team review should be reserved for genuine cross-cutting concerns, not applied as a default.
Enforce small PRs. The oldest advice in software engineering, and AI makes it more important, not less. AI tools make it trivially easy to generate large changes, but stacking them into smaller PRs after the fact is a rescue, not a discipline. The most effective teams size work for reviewability upstream and shape the work before AI starts generating code.
Allocate time for refactoring. A 67% refactoring advantage doesn’t happen by accident. It requires explicit engineering leadership decisions to invest in codebase health. The return on that investment compounds when AI tools are in play — clean codebases produce cleaner AI output.
Make the process selective, not universal. Formal approval on 96% of PRs means approval fatigue. Cross-team review on 51% of PRs means fragmented attention. Apply heavy processes where the risk is high (cross-cutting architectural changes, security-sensitive code, public API modifications) and trust teams to own the rest.
A Note On The Analysis
This analysis reveals what high-performing AI organizations look like in the data. It doesn’t fully answer how they got there. The practices that produce autonomous teams, small PRs, and healthy codebases are organizational and cultural. They involve specific engineering harness configurations, team topology decisions, CI/CD pipeline designs, and review automation setups that go beyond what aggregate metrics can capture.
Our advisory team has conducted in-depth interviews with engineering leaders at several of these high-performing organizations to understand the specific mechanisms behind these numbers. If your organization is navigating AI adoption at scale and wants to understand what separates the champions from the risk zone, reach out to our team for a detailed assessment.
The Bottom Line
AI code generation is a force multiplier, but it multiplies whatever engineering environment it operates in. In an organization with autonomous teams, small PRs, and a well-maintained codebase, AI makes good teams faster. In an organization with tangled ownership, large PRs, and accumulated technical debt, AI makes the problem worse faster.
The question isn’t whether to adopt AI. It’s whether your engineering foundations are ready for what AI will amplify.
Analysis based on 248,099 pull requests across a selected sample of engineering organizations with significant AI adoption. Organizations grouped by AI adoption level and defect rate. Defect rates computed from root-cause-analyzed PRs only (PRs that have been evaluated for whether they introduced production defects).